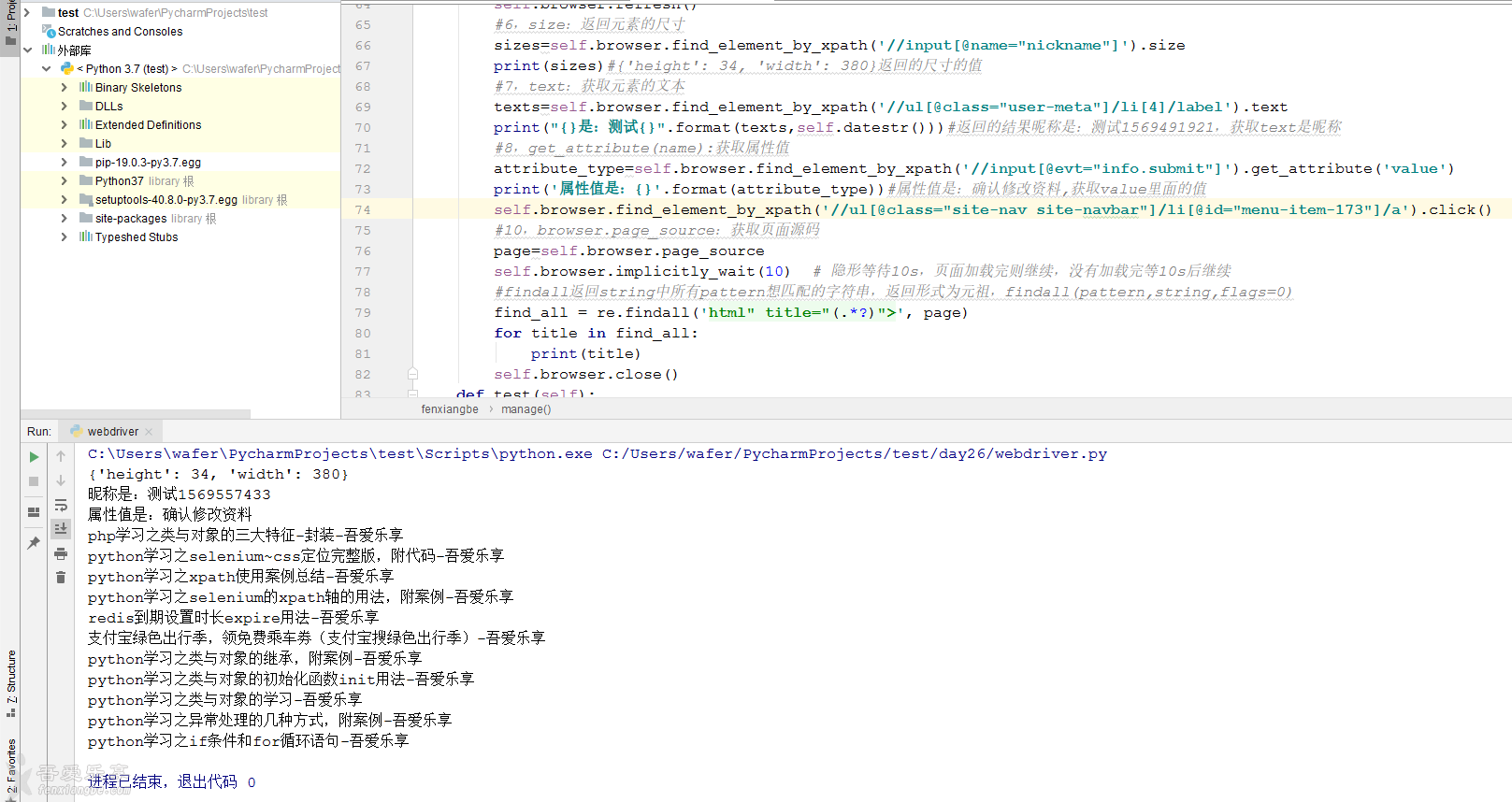
webdriver常用的方法
1,clear():清除文本
2,send_keys():输入文本
3,click():点击元素
4,refresh():刷新页面
5,submit():提交,功能同click(),但用的没有click广泛
6,size:返回元素的尺寸
7,text:获取元素的文本
8,get_attribute(name):获取属性值
9,is_displayed():设置该元素是否用户可见,可见返回true,否则返回false
10,getPageSource():获取页面源码
#coding:utf-8
from selenium import webdriver
import time
import re
'''
webdriver常用的方法
1,clear():清除文本
2,send_keys():输入文本
3,click():点击元素
4,refresh():刷新页面
5,submit():提交,功能同click(),但用的没有click广泛
6,size:返回元素的尺寸
7,text:获取元素的文本
8,get_attribute(name):获取属性值
9,is_displayed():设置该元素是否用户可见,可见返回true,否则返回false
10,driver.page_source:获取页面源码
'''
class fenxiangbe:
'''
driver,驱动打开浏览器
'''
def driver(self):
self.browser = webdriver.Chrome()
self.browser.maximize_window()
self.browser.get('https://www.fenxiangbe.com')
self.browser.implicitly_wait(10) # 隐形等待10s,页面加载完则继续,没有加载完等10s后继续
'''
登录
'''
def login(self):
self.driver()
self.browser.find_element_by_xpath('//a[@class="signin-loader"]').click()
self.browser.implicitly_wait(10) # 隐形等待10s,页面加载完则继续,没有加载完等10s后继续
# 9,is_displayed():设置该元素是否用户可见,可见返回true,否则返回false
time.sleep(1)
isdisplay = self.browser.find_element_by_css_selector('.sign-info>a').is_displayed()
if isdisplay:
self.browser.find_element_by_css_selector('#inputEmail').send_keys('测试')
self.browser.find_element_by_css_selector('#inputPassword').send_keys('ceshiceshi')
self.browser.find_element_by_xpath('//form[@id="sign-in"]/div/input[1]').click()
else:
print('可以注册')
'''
登录后点击会员中心进入管理端操作
'''
def manage(self):
self.login()
#self.browser.implicitly_wait(10) # 隐形等待10s,页面加载完则继续,没有加载完等10s后继续
time.sleep(1)
self.browser.find_element_by_xpath('//div[@class="topbar"]/a[last()]').click()
self.browser.implicitly_wait(10) # 隐形等待10s,页面加载完则继续,没有加载完等10s后继续
self.browser.find_element_by_xpath('//ul[@class="usermenu"]/li[4]/a').click()
#1,clear():清除文本
self.browser.find_element_by_xpath('//ul[@class="user-meta"]/li[4]/input').clear()
#2,send_keys():输入文本
self.browser.find_element_by_xpath('//ul[@class="user-meta"]/li[4]/input').send_keys('测试{}'.format(self.datestr()))
#3,click():点击元素
self.browser.find_element_by_xpath('//input[@evt="info.submit"]').click()
time.sleep(0.5)
#4,refresh():刷新页面
self.browser.refresh()
#6,size:返回元素的尺寸
sizes=self.browser.find_element_by_xpath('//input[@name="nickname"]').size
print(sizes)#{'height': 34, 'width': 380}返回的尺寸的值
#7,text:获取元素的文本
texts=self.browser.find_element_by_xpath('//ul[@class="user-meta"]/li[4]/label').text
print("{}是:测试{}".format(texts,self.datestr()))#返回的结果昵称是:测试1569491921,获取text是昵称
#8,get_attribute(name):获取属性值
attribute_type=self.browser.find_element_by_xpath('//input[@evt="info.submit"]').get_attribute('value')
print('属性值是:{}'.format(attribute_type))#属性值是:确认修改资料,获取value里面的值
self.browser.find_element_by_xpath('//ul[@class="site-nav site-navbar"]/li[@id="menu-item-173"]/a').click()
#10,browser.page_source:获取页面源码
page=self.browser.page_source
self.browser.implicitly_wait(10) # 隐形等待10s,页面加载完则继续,没有加载完等10s后继续
#findall返回string中所有pattern想匹配的字符串,返回形式为元祖,findall(pattern,string,flags=0)
find_all = re.findall('html" title="(.*?)">', page)
for title in find_all:
print(title)
self.browser.close()
def test(self):
self.driver()
# self.browser.find_element_by_xpath('//a[@class="signin-loader"]').click()
# self.browser.implicitly_wait(10) # 隐形等待10s,页面加载完则继续,没有加载完等10s后继续
# isdisplay = self.browser.find_element_by_css_selector('.sign-info>a').is_displayed()
# if isdisplay :
# print('可以登录')
# else:
# print('可以注册')
page = self.browser.page_source
self.browser.implicitly_wait(10) # 隐形等待10s,页面加载完则继续,没有加载完等10s后继续
# findall返回string中所有pattern想匹配的字符串,返回形式为元祖,findall(pattern,string,flags=0)
find_all = re.findall('html" title="(.*?)">', page)
for title in find_all:
print(title)
self.browser.close()
def datestr(self):
times=int(time.time())
return times
if __name__ == '__main__':
fen=fenxiangbe()
fen.manage()
#fen.datestr()
# fen.test()











评论前必须登录!
注册